Analisi
In questa fase i dataset identificati vengono analizzati per comprendere se esistano ostacoli alla loro apertura. Il Referente Dataset, infatti, dovrà accertare la priorità della pubblicazione, verificare o risolvere eventuali impedimenti di riservatezza e/o titolarità del dato e controllare che il dataset sia correttamente reso in formato aperto, cioè che sia dotato di valida licenza per la pubblicazione e che sia in linea con la vigente normativa sulla privacy.
Gli ostacoli più comuni alla pubblicazione di un dataset in formato aperto si riferiscono a:
- Proprietà dei dati
- Qualità del dato insufficiente
- Veridicità del dato non appurabile
- Dati soggetti ad obsolescenza
- Presenza di dati sensibili
- Costi di estrazione dalla fonte originaria non sostenibile.
- Possibili conseguenze negative per la pubblica sicurezza
- Altri problemi di natura giuridica.
Prima di procedere all’analisi di un dataset, è importante averne stabilito la priorità rispetto a quanto del patrimonio informativo dell’Ente è in attesa di pubblicazione. In particolare, i dataset indentificati possono essere categorizzati in:
- MUST – I dataset che rientrano in questa categoria hanno la massima priorità di pubblicazione e sono, quindi, di massimo interesse per la collettività;
- SHOULD – Il grado di priorità dei dataset è tale per cui essi devono essere pubblicati appena possibile, poiché di medio interesse da parte della collettività;
- COULD – La pubblicazione di questi dataset è potenziale e auspicabile, ma con un interesse ridotto per i futuri fruitori;
- WON’T – I dataset che rientrano in questa categoria hanno priorità bassa, pertanto non saranno pubblicati, se non eventualmente in futuro, in quanto non è significativo l’interesse della collettività nella loro pubblicazione.
L’esecuzione di tutte le attività propedeutiche all’apertura dei dati, come previste dal modello operativo degli Open Data, dipende da una valutazione complessiva del costo-opportunità di apertura. Ad esempio, si deve tenere conto del costo per adeguare il dataset al formato di pubblicazione richiesto, oppure del costo da sostenere per la dematerializzazione.
L’analisi, così come descritta nel documento di riferimento, è stata suddivisa in quattro sotto-fasi al quale il Referente Dataset deve prestare particolare attenzione. Le sotto-fasi sono:
- Analisi della riservatezza e della titolarità
- Analisi del formato e della struttura
- Analisi dei dati personali
- Conversione in formato aperto e metadatazione
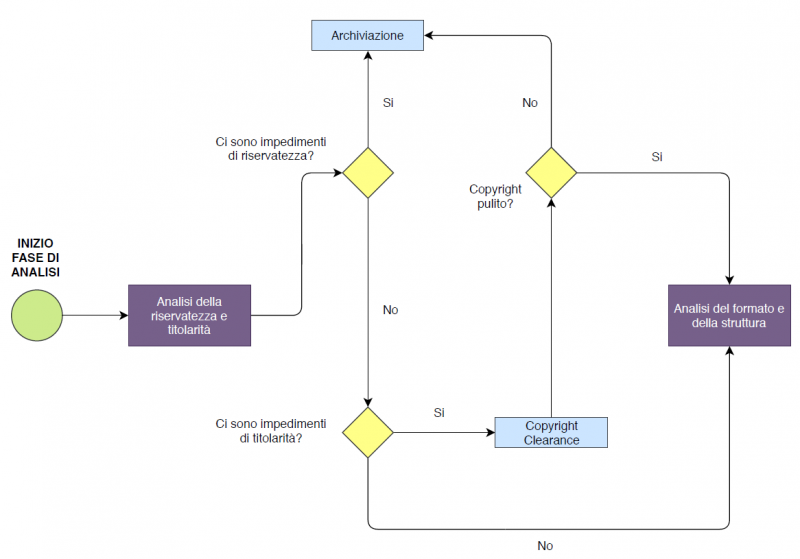
1. Analisi della riservatezza e della titolarità
- La sicurezza pubblica, la difesa nazionale, lo svolgimento di indagini penali o disciplinari;
- Il diritto di terzi al segreto statistico, industriale e commerciale, o altri vincoli di segretezza fissati in obblighi di legge;
- I diritti di proprietà intellettuale di terze parti;
- Il diritto alla protezione dei dati personali.
Per quanto concerne il tema della titolarità, sono considerati di proprietà dell’Ente i dati di cui dispone o che ha acquisito, direttamente e/o indirettamente, dai fornitori di servizi.
Per cui, coloro che detengono tali dati sono tenuti a fornirli all’Ente in forma disaggregata e possibilmente tabellare, nonché in formato aperto, ovvero, corredati da apposita scheda di metadatazione, per consentire all’Amministrazione di acquisirne la piena disponibilità.
Tuttavia, lo spostamento di dati da un sistema informativo ad un altro non modifica in alcun modo la titolarità dei dati. Quindi, rimane immutata la responsabilità sulla loro gestione, sulla loro esattezza e veridicità, così come previsto dall’art. 58 comma 1 del D.lgs. 82/2005. Ciò comporta che l’uso legittimo del dato in tutti gli altri casi (ossia dati formati da altri soggetti) avvenga ottenendo dal titolare apposita licenza che consenta la pubblicazione attraverso il processo di copyright clearance, che consiste nel predisporre un accordo o l’applicazione di una licenza aperta con il titolare del dataset, tale per cui sia ammesso il suo riuso e la sua diffusione da parte dell’Ente e da chiunque abbia poi accesso ai dati.
Idealmente, si dovrebbe provare ad ottenere che il detentore dei diritti sui dati rinunci a tutti gli interessi sull’opera, attribuendola al Pubblico Dominio con l’utilizzo dello strumento IODL (Italian Open Data License), dettagliata nella Sezione 6.2.4 del presente documento.
Per valutare la riservatezza di un dato, invece, può essere usata la seguente classificazione:
- Dati Pubblici – Possono essere pubblicati liberamente;
- Dati Riservati – Non possono essere pubblicati, perciò, devono essere archiviati;
- Dati Vincolati – Sono tutti i dati originati da terze parti o in possesso dell’Ente su cui, però, terzi detengono diritti di proprietà intellettuale ai sensi della Legge n. 633 del 22 aprile 1941 e/o diritti di proprietà industriale ai sensi del D.Lgs del 10 febbraio 2005, n. 30; tali dati potranno essere aperti soltanto dopo il processo di copyright clearance.
Il Referente Dataset deve chiaramente indicare nella scheda di metadatazione il nominativo e i dati di contatto del titolare del dato, nel caso in cui non sia l’Ente stesso.
Nel caso in cui il dato venga considerato non-idoneo alla pubblicazione, il Referente Dataset procederà con l’archiviazione del dataset, specificando se questa si renda necessaria per riservatezza, per non titolarità o per altre ragioni (ad esempio, costi di dematerializzazione troppo alti), in quanto tutti gli altri attori devono essere informati delle motivazioni applicate al processo di archiviazione di un dataset.
In particolare, se il dataset è stato analizzato in risposta ad una richiesta proveniente dagli attori sociali, si rende necessario dare un feedback diretto, ad esempio via posta elettronica, al richiedente in merito alla motivazione per cui si è stabilito che il dataset non possa essere pubblicato.
2. Analisi del formato e della struttura
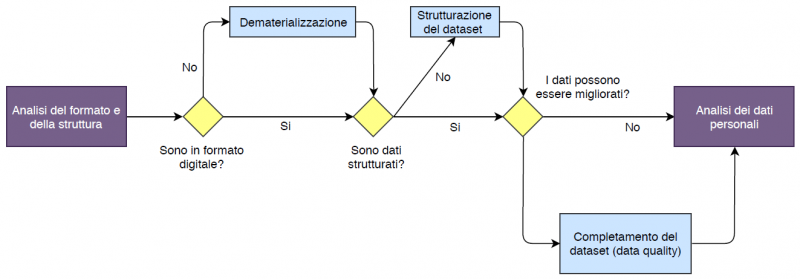
Il primo passaggio consiste nell’eventuale dematerializzazione dei dati, nel caso in cui l’Ente li detenga solo in forma cartacea: essendo la trasposizione in formato digitale un’operazione da effettuare necessariamente manualmente, è importante stabilire il grado di importanza del dataset da produrre e, quindi, confrontarlo con il costo per la sua resa in formato digitale.
Durante la dematerializzazione è necessario documentare accuratamente le caratteristiche, la quantità e il formato primario dei dati (tabelle, testo, immagini), ma anche il loro stato di conservazione e, in particolare, è bene prestare attenzione alla presenza di una o più delle seguenti problematiche:
- Assenza di dati in determinati periodi di tempo: ad esempio, mancano i dati di un anno o di una settimana; la completezza e continuità della cadenza temporale è fondamentale ai fini della creazione di serie storiche;
- Dati mancanti o illeggibili: ad esempio la mancanza di intere righe o colonne, così come l’illeggibilità dei dati a causa di formattazione o passaggio di formato.
In considerazione della molteplicità e della varietà di dati da esaminare, si rende necessaria una loro classificazione sulla base del formato/struttura e, quindi, della loro “leggibilità”. È a partire da questa classificazione che saranno poi effettuate una serie di operazioni volte ad ottenere un dataset pronto per la pubblicazione, cioè in formato digitale, strutturato e aperto.
A seconda del dato analizzato, gli attori responsabili del processo devono classificare la situazione del dato (se in formato digitale) all’origine tra le seguenti categorie e livelli:
- Dati grezzi: disponibili in formati che non consentono l’estrapolazione immediata degli stessi come ad esempio immagini nei diversi formati grafici (.gif, .jpg, .png, .bmp, etc) o documenti in formato proprietario Adobe PDF o Microsoft Word. Questi dati, senza trasformazioni, possono essere aperti con livello ★
- Dati strutturati: dati disponibili in formati – aperti o proprietari - che ne consentono l’elaborazione in forma strutturata; i dati strutturati sono, ad esempio, quelli inseriti in un file Excel e organizzati secondo righe e colonne e hanno il vantaggio di essere facilmente inseriti, archiviati, interpretati e analizzati; i fogli di calcolo in formato proprietario creati con Microsoft Excel (.xls, .xlsx) possono essere “aperti” con livello ★★, invece, se salvati in formati non proprietari (come .csv, .ods) raggiungono il livello ★★★.
- Database: di norma di questi dati è possibile scegliere il formato di esportazione più idoneo (es. XML, JSON o altri formati aperti). L’esportazione può produrre file classificabili con livello ★★★★ o ★★★★★ (Linked Open Data) se relazionati ad altri dataset.
Nel caso in cui l’Ente sia in possesso di dati grezzi (cioè non aperti e classificabili come ★), la trasformazione di questi in dati aperti dovrà essere valutata dal Referente Open Data, sia in relazione al valore dei dati, sia in termini di risorse, che di tempi.
Nel caso di dati a due stelle ★★ (strutturati in formato proprietario) di norma è necessario convertirli in formati aperti e raggiungere quindi un livello ★★★. Il Portale Open Data consente il caricamento anche dei dati a ★★, ad esempio nel formato .xls o .xlsx, tuttavia le linee guida di AgID sottolineano come la produzione e pubblicazione di dati aperti solo di ★ e ★★ non sia più ammessa. È, quindi, buon senso del Referente Open Data e del Referente Dataset fare quanto possibile far raggiungere ai dati da pubblicare almeno il livello ★★★.
Naturalmente, i database che potranno generare dati a ★★★★ o ★★★★★ avranno bisogno di competenze tecniche specifiche in quanto richiedono la costruzione di dataset basati su standard aperti definiti dal W3C (come RDF, SPARQL) per identificare le risorse, in modo che si possano creare collegamenti ai dati.
Le attività di “pulizia dei dati” con cui si intendono l’individuazione, la correzione o rimozione di record corrotti o inesatti, devono essere intraprese al fine rendere il dataset conforme agli standard richiesti, ma anche di effettiva utilità per il fruitore finale.
La strutturazione pertanto resta un momento fondamentale nel modello di conferimento dei dati perché permette di garantire la qualità dei dati, cioè non aventi dei difetti che ne possano impedire o rendere difficile l’analisi, l’interpretazione e il riutilizzo.
3. Analisi dei dati personali

Si parla di tecniche di trattamento per riferirsi all’insieme delle attività di individuazione degli strumenti e modi per la protezione dei dati sensibili, ovvero, di tutela della riservatezza dei soggetti a cui i dati fanno riferimento.
All’interno dello svolgimento delle funzioni istituzionali, gli Enti si occupano del trattamento dei dati senza pregiudicare le finalità di trasparenza e di comunicazione, che sono alla base degli Open Data.
La principale tecnica che elimina, o al più, minimizza del tutto l’utilizzo di dati personali è l’anonimizzazione, in quanto, il “dato anonimo” non può essere associato ad un interessato identificato o identificabile. La normativa sulla privacy fornisce esempi diversi di tecniche di anonimizzazione in relazione a specifiche categorie di dati quali:
- Anonimizzazione con chiave di collegamento o mascheramento: è il trattamento prescritto nel caso in cui i dati personali detenuti per scopi statistici siano oggetto di comunicazione a soggetti privati terzi; i dati, quindi, sono ceduti a terzi in una forma che rende impossibile il riferimento o l’associazione con l’interessato. In sostanza, l’interessato viene identificato da un codice e la chiave che crea il collegamento tra il codice e gli interessati rimane in possesso del Titolare del trattamento.
- Oscuramento: è il trattamento prescritto nel caso in cui, su richiesta dell’interessato, o su disposizione “d’ufficio” dell’Autorità giudiziaria, siano precluse l'indicazione delle generalità e degli altri dati identificativi dell'interessato in qualsiasi forma per finalità di informazione giuridica, su riviste giuridiche, supporti elettronici o mediante reti di comunicazione elettronica.
- Anonimizzazione in senso stretto: è il trattamento prescritto in caso di diffusione dei dati dei minori e delle parti nei procedimenti giudiziari in materia di rapporti di famiglia e di stato delle persone. La norma impone di omettere non solo le generalità e gli altri dati identificativi dei soggetti tutelati ma anche gli “altri dati relativi a terzi dai quali può desumersi anche indirettamente l’identità di tali soggetti”.
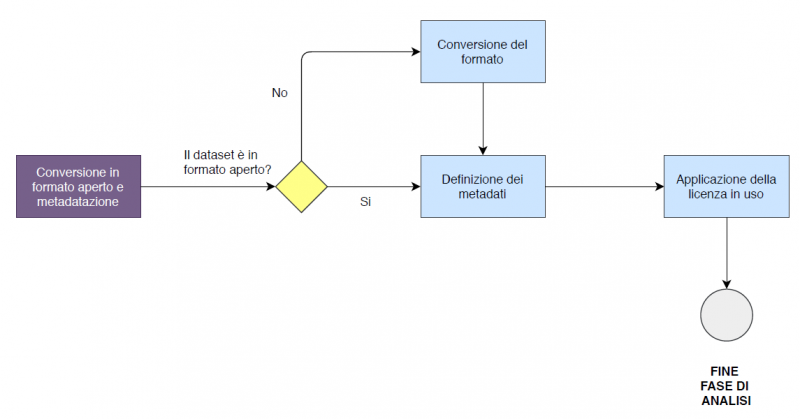
4. Conversione in formato aperto
- File Excel 2003 (.xls)
- File Excel 2007 (.xlsx)
- File DBase IV (.dbf)
- File Testo (.csv, .txt)
- File KML (.kml, .kmz)
- File Access 2003 (.mdb)
- ESRI Shapefile
Alcuni di questi formati non sono aperti, perché proprietari, come ad esempio i file Excel. Tuttavia, il Portale Open Data Veneto effettua una conversione implicita in uno o più formati aperti quali:
- CSV: formato per i file di testo apribile con qualsiasi lettore di file testuale
- XML/Atom: formato per file di testo aperto e standard; ha una struttura predisposta per permettere la lettura dei dati ad altri software generici; in particolare il formato XML Atom è adatto per la sottoscrizione di contenuti web, come blog o testate giornalistiche
- JSON: formato adatto per lo scambio dei dati in applicazioni client-server di ultima generazione.
- RDF/XML: il Resource Description Framework è lo strumento base proposto da W3C per la codifica, lo scambio e il riutilizzo di metadati strutturati e consente l’interoperabilità tra applicazioni che si scambiano informazioni sul web.
In seguito alla conversione in formato aperto devono essere definiti i metadati, che svolgono un ruolo importante nell’ottica di riutilizzo del dato, in quanto sono informazioni a corredo dei dataset, che ne esplicano il contenuto informativo.
La metadatazione ricopre un ruolo essenziale laddove i dati sono esposti a utenti terzi e a software. I metadati, letteralmente “dato su un (altro) dato”, infatti, consentono una maggiore comprensione e rappresentano la chiave attraverso cui abilitare più agevolmente la ricerca, la scoperta, l’accesso e il riuso dei dati stessi. Perciò, al fine di rendere tali dati interoperabili tra i cataloghi delle diverse Amministrazioni è di fondamentale importanza che il rilascio del dataset sia accompagnato da un insieme minimo di informazioni di carattere generale, ma redatto secondo regole standard.
Il Referente Open Data, con il supporto del Referente Dataset e gli esperti di dominio, deve identificare quali sono i metadati definitivi che verranno pubblicati con il dataset nel Portale Open Data Veneto.
I dataset possono essere soggetti a cambiamenti nel tempo, aggiornamenti o correzioni, perciò è bene che il Referente Dataset garantisca l’allineamento e la validità tra i metadati e i dati modificati. I riferimenti temporali nei metadati devono includere la data di creazione dei metadati e quella del loro ultimo aggiornamento.
Per la descrizione del “modello dei metadati” che guida la metadatazione, si rinvia alle “Linee Guida Nazionali per la valorizzazione del Patrimonio Informativo Pubblico" (2017) di AgID. Il modello si focalizza sugli aspetti qualitativi dei metadati e la classificazione qualitativa si fonda su due fattori principali: legame tra dato e metadato e livello di dettaglio.
Le licenze definiscono le condizioni e le modalità di riutilizzo dei dati pubblici e dei documenti contenenti dati pubblici, consentendone la più ampia e libera utilizzazione gratuita, anche per fini commerciali, in conformità all’art. 8 del D.Lgs. 36/2006 e ss.mm.ii.
La licenza di riferimento è la Italian Open Data License (IODL) v2.0, che ha lo scopo di consentire all’utente di condividere, modificare, usare e riusare liberamente la banca di dati, i dati e le informazioni annesse, anche a scopi commerciali, a condizione che venga citata la fonte. Questa licenza mira a facilitare il riutilizzo delle informazioni pubbliche nel contesto dello sviluppo della società dell'informazione.
Con tale licenza è possibile:
- Riprodurre, distribuire al pubblico, concedere in locazione, presentare e dimostrare in pubblico, comunicare al pubblico, mettere a disposizione del pubblico, trasmettere e ritrasmettere in qualunque modo, eseguire, recitare, rappresentare, includere in opere collettive e/o composte, pubblicare, estrarre e reimpiegare le informazioni;
- Creare un lavoro derivato ed esercitare su di esso i diritti di cui al punto precedente, per esempio attraverso la combinazione con altre Informazioni (mash-up).
Quanto esposto nei due punti precedenti è valido a condizione di:
- Indicare la fonte delle informazioni e il nome del Licenziante, includendo, se possibile, una copia di questa licenza o un collegamento (link) ad essa.
- Non riutilizzare le Informazioni in un modo che suggerisca che abbiano carattere di ufficialità o che il Licenziante approvi l'uso che se ne fa delle informazioni;
- Prendere ogni misura ragionevole affinché gli usi innanzi consentiti non traggano in inganno altri soggetti e le informazioni medesime non vengano travisate.
E’ consentito esercitare i diritti concessi con questa licenza in modo libero e gratuito, anche qualora la finalità sia di tipo commerciale. Inoltre, questa licenza non intende in alcun modo creare ulteriori diritti in capo al Licenziante rispetto a quelli previsti dalla legge sul diritto d'autore o ridurre, limitare o restringere alcun diritto di libera utilizzazione o l'operare della regola dell'esaurimento del diritto od altre limitazioni dei diritti sulle Informazioni derivanti dalle leggi applicabili.
Conformemente a quanto disposto dall'art. 52, comma 2 del CAD (c.d. Open by Default), i dati già pubblicati sul Portale Open Data Veneto, qualora non sia indicata una specifica licenza, si intendono rilasciati come dati di tipo aperto e sono disponibili per il riutilizzo “come se forniti di una licenza”, che in tal caso non può prevedere alcuna specificazione e di fatto il riutilizzo si allinea ad una Licenza IODL, ad eccezione dei casi in cui la pubblicazione riguardi dati personali.
Qualora ricorrano giustificati motivi tali da orientare la scelta verso una licenza standard diversa da quelle di riferimento, la specifica licenza, per quanto possibile, deve rispettare il principio di consentire la più ampia e libera utilizzazione gratuita, anche per fini commerciali e con finalità di lucro.
Tutte le informazioni raccolte durante la fase di analisi saranno strumentali alla compilazione della Scheda Informativa del dataset, che dovrà essere compilata al fine di poter pubblicare il dataset nel Portale Open Data. Il format che il Referente Dataset si troverà a compilare è come quello esposto e descritto nell’Allegato A3 a questo documento.